What is data federation
Data Federation is an advanced data management technique that allows an organization to aggregate and manage data from multiple sources without needing to physically merge these sources into a single location. This approach enables businesses to view and analyze consolidated data in real-time, enhancing decision-making and operational efficiency. Data federation allows for accessing and querying data from different sources as if they were stored in a single database without physically moving or copying the data. This capability is especially crucial in today's fast-paced business environments, where access to timely and accurate information is a key competitive advantage.
By leveraging data federation technologies, organizations can create a unified data layer that abstracts the underlying complexity of diverse data models and formats. This makes it easier for users to access and analyze critical data across various systems, including on-premises databases, cloud storage, and even big data platforms, without the need for time-consuming ETL (Extract, Transform, Load) processes.

Data federation aggregates data from multiple sources without physically moving or copying data.
Data federation with Tom Sawyer Perspectives
Our mature, data-agnostic graph platform, Perspectives, includes data federation capabilities that combine data residing in different data sources and with different data structures providing enterprises with real-time access to a unified view of their data.
The process of data federation involves connecting to data sources using provided integrators, extracting the schema to understand the structure of the data, and binding the data source and the schema. This procedure is essential for achieving the flexibility and efficiency that data federation enables.
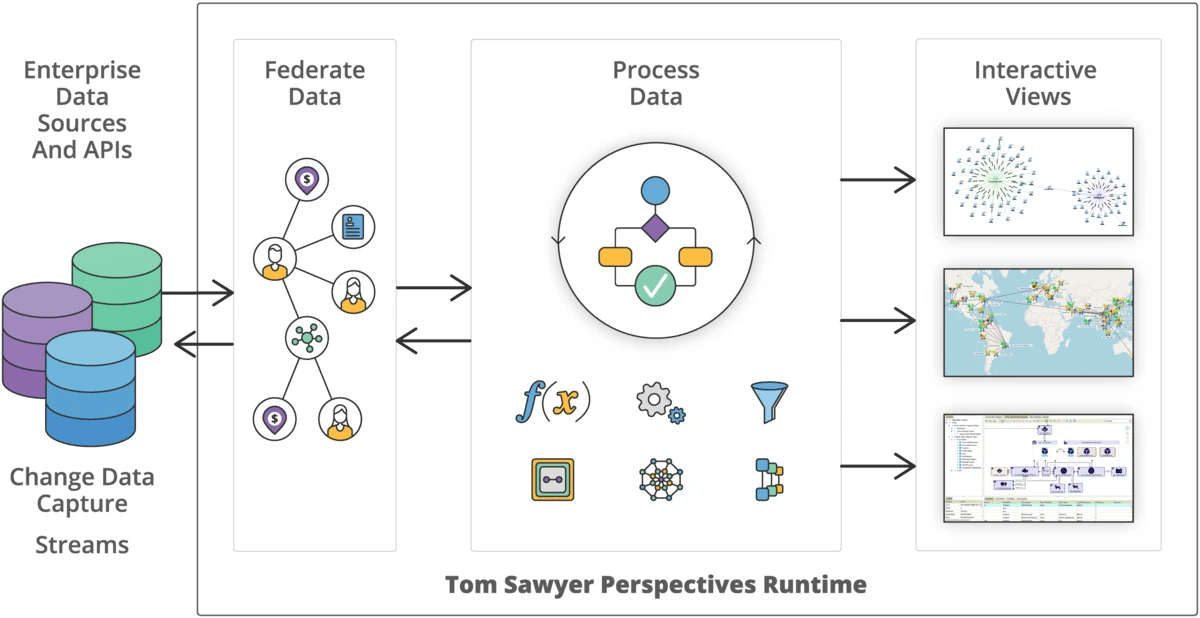

Benefits of federating data
Modern enterprises struggle to manage their data stores efficiently and cost-effectively, and in many cases must continue to maintain legacy systems that use older data storage technology. The problem is compounded by the need for businesses to understand and utilize the data contained in these various systems to their competitive advantage.
Uncovering the important data in these data silos requires purpose-built techniques and tools to enable efficient and improved decision-making.
Data federation has become indispensable for organizations seeking to harness the power of their collective data assets. The benefits of data federation extend far beyond data consolidation, touching every aspect of an organization's operations and strategic decision-making. Here's why data federation is crucial for organizations navigating the complexities of the modern data-driven world of fast-growing data and data silos:

Informed decision-making
Having a consolidated view of data from different systems provides a single source of truth for accurate decision-making.
This comprehensive insight enables businesses to make more informed choices, driving strategic initiatives and operational improvements.

New insights exposed
With federated data, you can apply specialized visualization and analysis techniques to expose interesting and previously unseen results.
This approach provides a holistic view across the entire enterprise for a more accurate and enhanced view.

Increased productivity
Data consumers have a single source of truth to consult, enabling them to make mission critical decisions quickly and accurately.
This accessibility significantly boosts productivity, allowing users to focus on analysis rather than data collection.

Improved data agility
Eliminating latency concerns and the need for data migration or synchronization, data can be accessed and queried in real-time.
This improvement in data agility and flexibility is crucial for organizations that need to respond rapidly to changing market conditions or internal demands.

Cost- and time-savings
Data federation reduces the dependency on IT teams to develop custom data integrations or move data around, leading to significant cost- and time-savings.
Organizations can allocate these resources to more strategic initiatives, enhancing overall efficiency and competitiveness.

Eliminate data redundancy
Unlike traditional data integration methods that often require moving or copying data to a central data lake or data warehouse, data federation allows data to remain in its source systems.
This approach minimizes redundancy, reduces storage costs, and simplifies data management.

Real-time data access
Data federation facilitates instant access to the latest data across the enterprise, enabling real-time analytics and timely decision-making.
It also offers enhanced responsiveness so organizations can quickly respond to internal and external developments, gaining a competitive edge.

Flexibility and scalability
Data federation offers exceptional flexibility and scalability, accommodating the evolving data landscape of an organization without significant restructuring or investment.
It seamlessly integrates new data sources and scales to handle increasing data volumes and complexity.

Enhanced data quality and governance
By centralizing access to data through a virtual layer, data federation facilitates better data quality management and governance practices.
It provides tools for monitoring, cleaning, and securing data across the organization, ensuring compliance with standards and regulations.